Spark read csv
spark.read.csv(path) / failfast mode / options
Spark读取csv和json读取一样,都支持3种模式:
- permissive. 默认模式,bad record的所有字段会设置为null。
- dropmalformed. bad record会被直接丢弃。
- failfast. bad record会导致作业失败,抛出BadRecordException。
这3中模式实际上定义了应该如何处理bad record。是丢弃呢?还是设置字段为null呢?还是直接失败?
BadRecordException是在parse csv / json失败时会抛出的异常。Spark中parse csv使用UnivocityParser,parse json使用JacksonParser(fastxml.jackson)。同样,如果要知道parse过程中是否有异常需要设置mode为failfast。
csv parse两种情况会导致parse失败,一是schema.fields.length不匹配;二是字段转化为schema的对应类型失败。如果遇到读到所有的值都为null的情况,请考虑是哪种情况导致的parse失败。
val spark = SparkSession
.builder()
.appName("test")
.master("local[*]")
.getOrCreate()
import spark.implicits._
val csv = "a, b ,c,d,"
val ds = Seq(csv).toDS
val df = spark.read.csv(ds)
df.show()
df.write
.option("emptyValue", "")
.option("ignoreLeadingWhiteSpace", value = false)
.option("ignoreTrailingWhiteSpace", value = false)
.mode("overwrite")
.csv("/tmp/output")
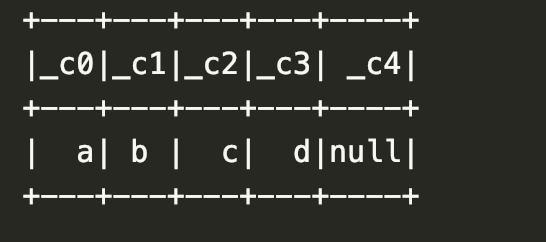
df.show()的结果如下图,注意最后一个comma会导致额外的一个null列,且c1的前缀空格和后缀空格没有被删除。而在write csv的时候为了保证产生和read完全一致的数据,需要在code中设置一些option,否则前后缀空格在write的时候会被删除,且空值会被double quotes代替。
csv格式支持的所有option及默认值请参考官方文档。