Spark partitions - A review
partitions决定了数据上的并行程度,比如100个分区那么理想情况下可以有100个task并行处理100个分区的数据。在资源充足的情况下,分区数越多并发程度(parallelism)越高执行速度越快吞吐量越大。
一个executor对应一个jvm进程,可以并发运行多个task。多个task可存在于同一个jvm进程中,意味着他们可以共享memory,比如broadcast过来的维表数据。默认一个task运行需要1个core,executor-cores决定了executor可以并发运行的task数目。一个partition需要一个task去处理。
注:RDD是typed low level的api, Dataset(typed) or DataFrame(untyped)是spark引入catalyst engine之后加入的high level api,对数据pipeline的ETL做了一些优化比如filter push down啊,codegen等等。
partitions number是怎么确定与变化的?
-
RDD, spark.default.parallelism决定了RDD partitions的数目.
import org.apache.spark.sql.SparkSession object SparkPartitions { def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .master("local[*]") .config("spark.default.parallelism", 100) .getOrCreate() import spark.implicits._ val rdd = spark.sparkContext.parallelize(Seq(1, 2, 3)) println(rdd.getNumPartitions) // 100 } } -
ShuffledRDD or CoGroupedRDD等 partition number为upstream RDDs的最大partition数。
-
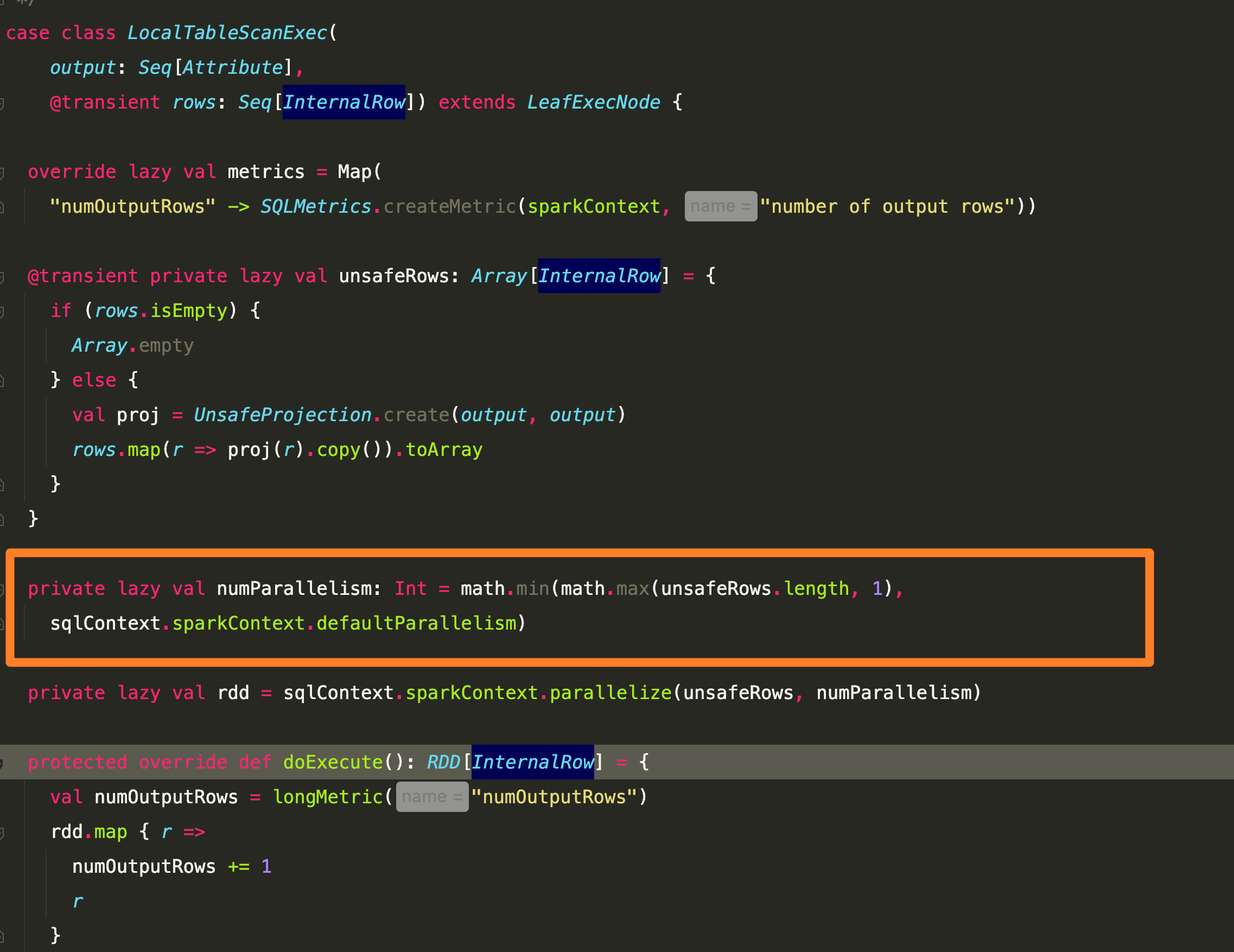
DataFrame, 其初始分区数由data source实现决定,体现为data source对应的物理执行计划定义了如何获取分区数据。如下例基于local Seq构建的DataFrame,实际分区数为min(rowsNumber, defaultParallelism).
import org.apache.spark.sql.SparkSession object SparkPartitions { def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .master("local[*]") .config("spark.default.parallelism", 100) .getOrCreate() import spark.implicits._ val df = Seq(1, 2, 3, 4).toDF println(df.rdd.getNumPartitions) // 4 = min(4, 100) } }local 数据的执行逻辑在SparkPlan(物理计划)LocalTableScanExec中, 对应的LogicalPlan为LocalRelation.
-
df.repartition, 可指定partition num & partition expression,涉及到shuffle。 会根据partition expr选择不同的partitioning方式。共3种: round robin(default), hash partition, range partition.
round robin: 顾名思义,row随机分配到不同的partition。
hash partition:根据partition key的hash值分配到不同的partition。
range partition: 根据key所在range分区。range的决定由蓄水池抽样算法进行,每个partition sample一定数量的数据collect到driver来决定区间范围。
如果没指定分区数,比如
df.repartition(),则会以spark.sql.shuffle.partitions的配置作为分区数, 默认值为200。 -
df.groupBy or groupByKey() 涉及shuffle操作,分区数由配置
spark.sql.shuffle.partitions决定。可以通过explain()方法打印分区数, 如下:import org.apache.spark.sql.{SparkSession, functions} object SparkPartitions { def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .master("local[*]") .config("spark.default.parallelism", 100) .getOrCreate() import spark.implicits._ val rdd = spark.sparkContext.parallelize(Seq(1, 2, 3)) rdd.repartition(10) val df1 = rdd.toDF df1.groupBy("value").agg(functions.max("value")).explain() } }
-
df1.join(df2), join操作的分区数由两个df的分区数决定。SparkStrategies定义了如何执行join操作。大致有5类:
BroadcastHashJoin: 小表会被broadcast到大表分区构建hash表,分区数由大表分区数决定。
ShuffledHashJoin: 两表数据都会根据join key shuffle(hash)到不同的分区,分区数由
spark.sql.shuffle.partitions决定。最终对同一分区的数据做join,其中小表可以build hash relation和另一表join。最终执行计划类似于 ShuffleExchangeExec(df1) hash join ShuffleExchangeExec(df2)。SortMergeJoin: 两表数据都会根据join key shuffle(hash)到不同的分区,分区数由
spark.sql.shuffle.partitions决定。最终对同一分区的数据做merge sort join。最终执行计划类似于 ShuffleExchangeExec(df1) sort merge join ShuffleExchangeExec(df2)。BroadcastNestedLoopJoin: 类似BroadcastHashJoin,只是小表直接loop不构建hash表。
CartesianProductJoin: 两表构建笛卡尔积,最原始的join方式。partition数目为df1.partitions * df2.partitions,这种join非常低效。